Chatbots everywhere, handy assistants in applications, AI is booming and particularly generative models. More than a year after the disruptive release of ChatGPT lots has happened. Language models are everywhere and tooling to run these are becoming easier as well. Let’s take one of these local serving models, Ollama and create a Visual Studio Code extension that will use this model server for answering questions about our code base using one of the community AI models.
If you are impatient and more curious about the actual implementation, here you can find the code that is used to write this blog.
What is Ollama
Ollama is a large language model server, which took its inspiration from docker. Similar like docker where you can pull container images, you can pull models. As with Docker files, the sources for models can vary as well. You can find compatible models at the Ollama Library or on model sharing platforms like HuggingFace. Once a model is pulled it can be easily queried using a rest api. Ollama also offers functionality to enrich these models by adding more context, to allow better performance for the use-case it is possible to tweak the model, similar as you would add functionality to a docker image.
After installation of Ollama, a rest API is running and we have a cli tool available called ollama. With the cli tool we can download and run models. There are lots of models available and these models come in different shapes. The size of a model is indicated by the number of parameters, which is sort of the size of the brains of the model. The higher the number, the ‘smarter’ the model is. Or more accurate, the more information is stored inside the model. This also comes with a cost, models with more parameters take more diskspace, but also require more computation power.
A model is as good as its data which is used to train the model. Depending on the training data, the model may have more specific domain knowledge than other models. If a model is trained only with English texts, it will not be able to respond to Dutch questions, or respond with Dutch answers. Same goes with programming languages, which is relevant if you want the model to produce, or understand code.
Next to the data used for training, there are also different type of models. If you want to translate text from one language to another, you will get the best performance when using a model that is trained to do that particular use-case, rather than a model that is trained to respond to chat messages.
For our chat integration, we will take the most popular model for coding we can find on the Ollama Library. This is the codellama model which is a chat model based on the popular llama2 model (from meta) and has been finetuned for coding related question. Downloading the model can be done with ollama pull codellama and it will by default download the smallest available model. To download a bigger model, you can add a tag specifying the flavour you want instead. If we type ollama run codelama we can chat with the model a bit.
Visual Studio Code Extensions
With a running Ollama server and a downloaded model we are good to go to integrate it in some other component. In our case, we want to be able to chat with these models in Visual Studio Code (vscode from now on). Fortunately, vscode can be extended with functionality through its extension system. Extensions are written in typescript, and there is a tool available that can be used to easily bootstrap the code base.
Let’s bootstrap our extension: npx --package yo --package generator-code -- yo code. With this we get a complete typescript project. The actual logic of the extension is bootstrapped in src/extension.js. Since we also want to integrate with ollama, let’s add the ollama dependency as well npm i ollama.
Our first goal is to get a response from Ollama in vscode. To do this we need to import the ollama package and extend the vscode user interface to execute our code based on some action. One of the integration points with the editor is adding commands (which can have short-cut keys as well). Commands are triggered via the command pallete, which can be opened with Cmd+Shift+P or Ctrl+Shift+P. To add a command to the extension, it needs to be declared in the package.json and registered inside the extension. The code that needs to be added to the extension.ts file is shown below.
1let gencmd = vscode.commands.registerCommand('ollacode.generate', () => {
2 Ollama({ host: 'http://localhost:11434' }).then( ollama => {
3 ollama.chat({
4 model: 'codellama',
5 messages: [{ role: 'user', content: 'What kind of music do you get if you combine a TR-909 with a TB-303?' }],
6 }).then( data => {
7 vscode.window.showInformationMessage(data.message.content);
8 });
9 });
10});
11context.subscriptions.push(gencmd);
The codeblock shows some interesting details. The Ollama chat method takes two parameters, model and messages. In model we just reference the model we downloaded earlier. The second parameter is an array of messages. In our call we only provide one message, and we set a role (user) to this particular message. This is our user prompt. Other available message types are system and assistant. A system message is basically an instruction you can give how the model should react, and the assistant messages should be populated with the responses we got from the previous calls. By providing a full flow of user and assistant messages, the model knows the context of the chat and can react on previously mentioned subjects. These details transform the chat into a conversation by introducing memory.
Once we did the call to Ollama, we call the vscode Api to present a pop-up with the answer. Although a nice achievement, it makes more sense to ask questions about certain selections of code within the editor. For example, wouldn’t it be nice if we could ask our model to explain a certain piece of code for us instead of the static question we did now? This is easy as well, and can be done with:
1const editor = vscode.window.activeTextEditor;
2if (editor) {
3 const selectedCode = editor.document.getText(editor.selection);
4}
At this point we were using the standard notifications of vscode to get our response. Although this a nice achievement, it makes more sense to ask questions about certain selections of code within the editor instead of the static question we just asked. We could replace the selected text with the responses, but a more user friendly approach would be that the messages would appear in their own window. One of the possibilities is using a regular editor window, similar to the markdown previewer. This is not recommended, and a more elegant approach is to introduce a webview similar to the standard webviews like the explorer and git webview. The user can move these windows to his own liking as well.
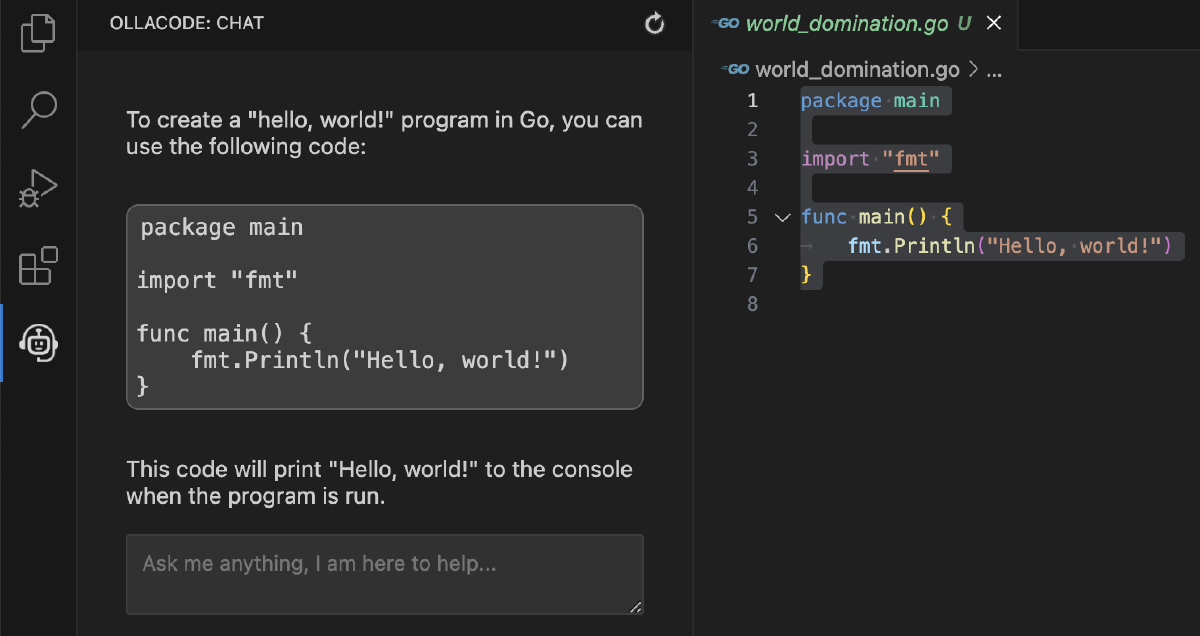
To create such a webview we need to create our own webview provider and declare our webview in the package.json. The webview in itself is a web page hosted in an iframe. The webview provider will provide the base html. To create an actual usefull ui we need to create a small frontend app for this. Our app loads the standard webview ui toolkit, and adds a messaging channel between the webview frontend and the extension. This frontend app needs to be build as well, as it is separate from the extension. The details go out of scope of this blog, but if find yourself examing the code used to write this blog, this is the reason why the extension is build using esbuild. Building the extension now required both building the extension itself and the required resources for the webview.
More commands, more prompts
With the webview interface at hand, it becomes already a nice chat application that we can easily open up in our vscode editor. Let’s add some more specific commands to our great tool. For example, it would be nice if we can ask the model to find bugs, or improve the given code. The messages we get back are also very lengthy and we typically ask these questions to get quick answers.
In our case, we want to instruct our model to respond with concise answers, and to make sure it’s not distracted by other topics we want to make it clear that we are using the model to help software engineers with coding questions. This is exactly what the system message in the Ollama Api is intended for, a metaprompt that sets the base of the conversation. Let’s add a system-prompt You are a chatbot answering software engineering coding questions. Respond with concise answers. to improve the responses.
To implement our other ideas we create a few prompts similar to Improve the given code-block:. After each prompt we add the codeblock it should take into consideration. By optimising the prompts the model is likely to give better results. This optimal prompt for the use case can differ per model. Usually the more context the model is given in the prompt, the better it is able to provide the desired output. In some cases the best result is met when the task is split over multiple prompts. Not that different from a regular conversation, where a dialog gives better results than a single question. This process is called prompt engineering.
Since the model keeps context when asking questions, it makes sense to be able to reset this context. In the demo extension we added a reload chat button to the chat webview. Also to make it easier to experiment with different models and prompts, the demo application also includes a few configurable settings. If you are interested in how this works, I encourage you to examine the repository, as it goes outside of the scope of this blog.
Conclusion
This is a very basic implementation of using large language models in vscode. We focussed specifically on the chat functionality, which gave us a nice chat window in vscode where we could talk about our selected source-code. The performance heavily depends on the underlying model and how the model is instructed. Another popular use-case is code completion, which differs from chat, as you would use the generate Api instead. Hopefully this blog gave you an idea how these extensions are made and inspired you to create your own or contribute to one of the many existing open source extensions available.

 Vincent van Dam
Vincent van Dam


