Door het automatisch bijwerken van je base images op je containerplatform is het mogelijk om de nieuwste versies op je OpenShift platform te hebben. Het kan natuurlijk ook voorkomen dat per direct een nieuwe base image gebouwd moet worden. Dit moet je dan met de hand kunnen doen. Wat nu?
Inleiding
In de voorgaande blog over de HCS Base Updater heb ik kort geschreven wat de HCS Base Updater is, hoe het werkt, waarom je hem zou moeten gebruiken en hoe je hem gebruikt. Heb je deze nog niet gelezen? Bekijk hem dan hier!
Het kan natuurlijk zo zijn dat in sommige gevallen je niet op een trigger van Knative wil of kan wachten.
Wanneer bijvoorbeeld Knative niet meer zou functioneren, betekent dit dat de base images niet meer automatisch bijgewerkt worden, of dit nu komt door een wijziging zoals een update of om andere redenen. In die gevallen zou je dus graag de on-demand pipeline willen hebben, zodat je niet meer afhankelijk bent van Knative voor het laten functioneren van de pipelines.
De werking van de on-demand pipeline
Bij het bouwen van de on-demand image pipeline is gedacht aan de herbruikbaarheid van de Tekton Tasks.
Hierdoor hoeft er niet veel gewijzigd te worden of te worden herbouwd. Dat is ook meteen een van de grote voordelen van Tekton (lees het hier terug in mijn blog over Cloud Native Tekton Pipelines).
De informatie die Knative verzamelt, wil je op een handmatige manier aan de on-demand pipeline geven.
Dus de ImageStream met ImageStreamTags wil je meegeven aan de pipeline.
Hierdoor hoeft de logica in de bestaande Tekton Tasks niet gewijzigd te worden en hoeft er alleen maar een Task aan toegevoegd te worden.
De on-demand pipeline bestaat eigenlijk uit bijna exact dezelfde stappen als de automatische variant. Laten we eerst nog even kort kijken naar de build-base-image pipeline.
De build-base-image pipeline heeft 3 Tasks.
graph LR;
git-clone --> check-imagestream;
check-imagestream --> build-base-images;
De nieuwe on-demand-build-base-image pipeline heeft 4 Tasks.
graph LR;
git-clone --> check-imagestream;
check-imagestream --> get-imagestream-tags;
get-imagestream-tags --> build-base-images;
Hierboven is te zien dat de nieuwe on-demand-build-base-image pipeline een extra Task heeft.
Deze get-imagestream-tags Task heeft 2 parameters: De imagestream-name en de input-tag-array, waarbij de laatste optioneel is en niet vereist voor het functioneren van de pipeline.
Wanneer de automatische build-base-image pipeline gaat draaien, komt de correcte informatie vanuit Knative de pipeline binnen. Die informatie voor de Tasks willen we ook in dat exact zelfde formaat in de on-demand-build-base-image pipeline. Dat gebeurt ook in deze nieuwe Task (get-imagestream-tags). Maar wat gebeurt er precies in die Task?
De logica in deze Task kijkt eerst of er naast de opgegeven ImageStream ook ImageStreamTags worden meegegeven om te bouwen.
Wanneer dit niet het geval is worden alle ImageStreamTags, on the fly, opgehaald van de bijbehorende ImageStream.
Deze opgehaalde ImageStreamTags worden in het correcte formaat opgeslagen zodat deze beschikbaar zijn voor de volgende Task, namelijk de build-base-images Task.
Naast dat deze ImageStreamTags worden opgehaald, kunnen ze ook handmatig worden meegegeven. Dan moet minimaal 1 ImageStreamTag worden opgegeven. Meer kan natuurlijk altijd.
Er vindt onder water een controle plaats om te kijken of de ImageStreamTag bestaat. Wanneer dit niet het geval is (of er natuurlijk een typo is gemaakt), dan komt dit netjes terug in de logs van de pipeline.
Bij het handmatig geven van ImageStreamTags worden deze, net zoals bij het ophalen hiervan, in het juiste formaat opgeslagen voor de volgende Task.
De on-demand pipeline in de praktijk
Bij de automatische pipeline worden de ImageStream en ImageStreamTag automatisch ingevuld door de informatie van Knative.
In de on-demand-build-base-image pipeline moeten deze met de hand ingevuld worden. Dat kan eenvoudig gedaan worden.
Bij de imagestream-name kan de ImageStream ingevuld worden en bij de input-tag-array kunnen de ImageStreamTags opgegeven worden. In het voorbeeld hieronder staat alleen 3.8. Omdat dit een array is kunnen er gewoon zoveel tags als gewenst meegegeven worden.
Complexer is het niet om de on-demand pipeline af te trappen! Het enige wat moet gebeuren is het aanmaken van deze PipelineRun:
1apiVersion: tekton.dev/v1beta1
2kind: PipelineRun
3metadata:
4 generateName: test-on-demand-build-base-image-
5spec:
6 params:
7 - name: imagestream-name
8 value: python
9 - name: input-tag-array
10 value:
11 - "3.8"
12 pipelineRef:
13 name: on-demand-build-base-image
14 workspaces:
15 - name: base-images-git
16 volumeClaimTemplate:
17 spec:
18 accessModes:
19 - ReadWriteOnce
20 resources:
21 requests:
22 storage: 512Mi
Onderstaande screenshots laten het verschil zien tussen beide pipelines via de web console van OpenShift.
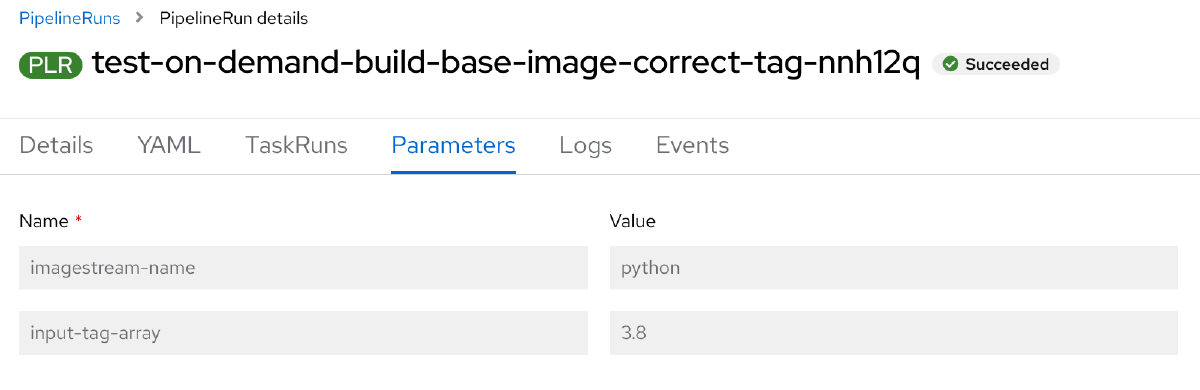
Bonus! Automatische on-demand pipeline tests
Als bonus op de on-demand pipeline zijn er ook een aantal tests geschreven om te controleren of de pipeline zijn werk goed doet. Dit zijn 6 test PipelineRuns met verschillende waardes in de parameters om de volgende scenario’s af te vangen:
- Correcte tag van ImageStream (een enkele ImageStreamTag is opgegeven)
- Correcte tags van ImageStream (meerdere bestaande ImageStreamTags zijn opgegeven)
- Incorrecte ImageStream (door bijvoorbeeld een typo of niet bestaande ImageStream)
- Incorrecte tag van ImageStream (door bijvoorbeeld een typo of niet bestaande ImageStream)
- Incorrecte tags van ImageStream (door meerdere incorrecte ImageStreamTags)
- Geen tag (wanneer geen ImageStreamTag is opgegeven)
Om deze PipelineRuns te starten en een controle uit te voeren, is een script gemaakt welke oude PipelineRuns opruimt en de nieuwe start. Dit script heeft ook output en laat zien welke tests zijn geslaagd of nog bezig zijn.
Dat overzicht van het script ziet er als volgt uit.
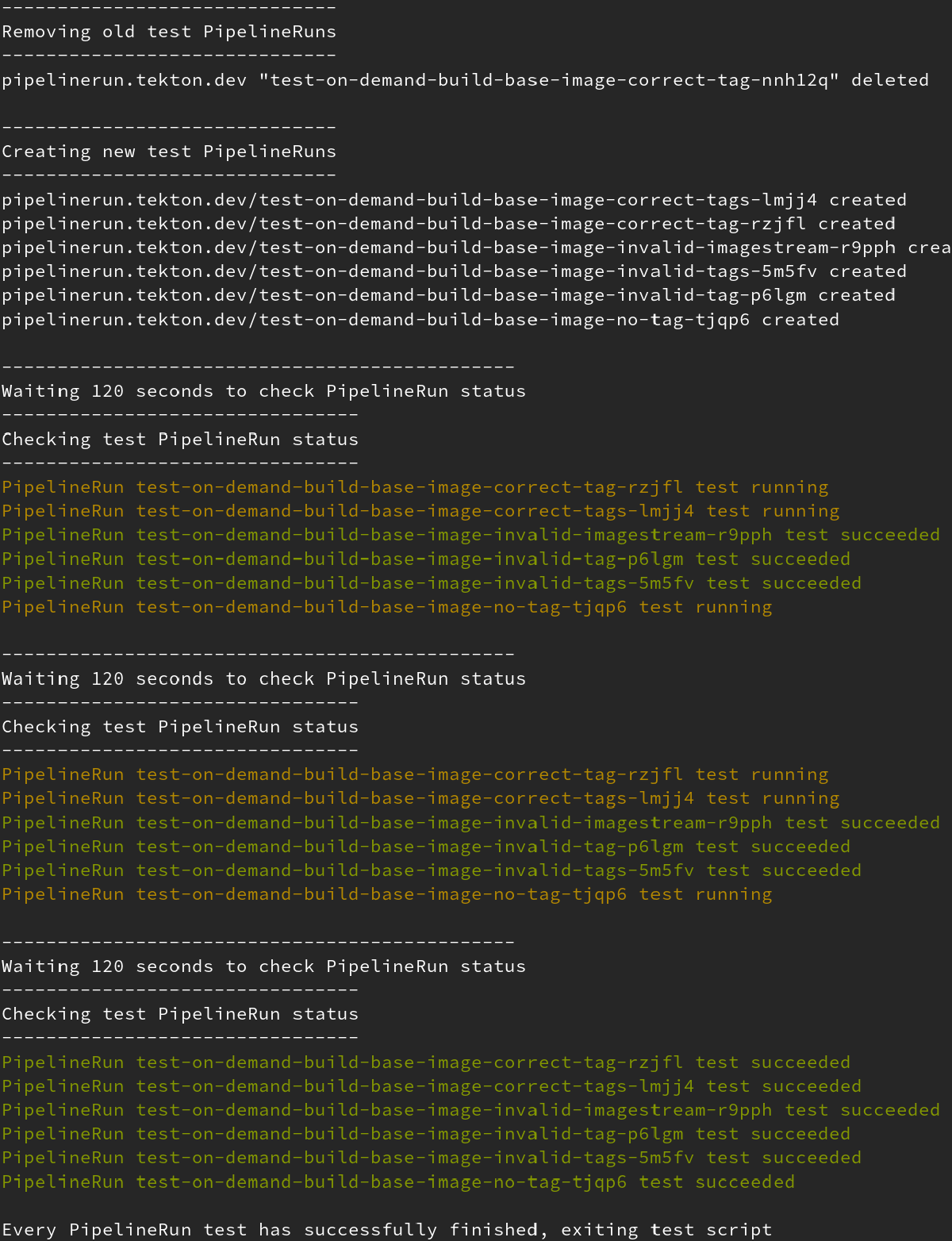
De vorige afbeelding heeft laten zien dat de tests allemaal geslaagd zijn. Dat kunnen we vergelijken met de volgende afbeelding.
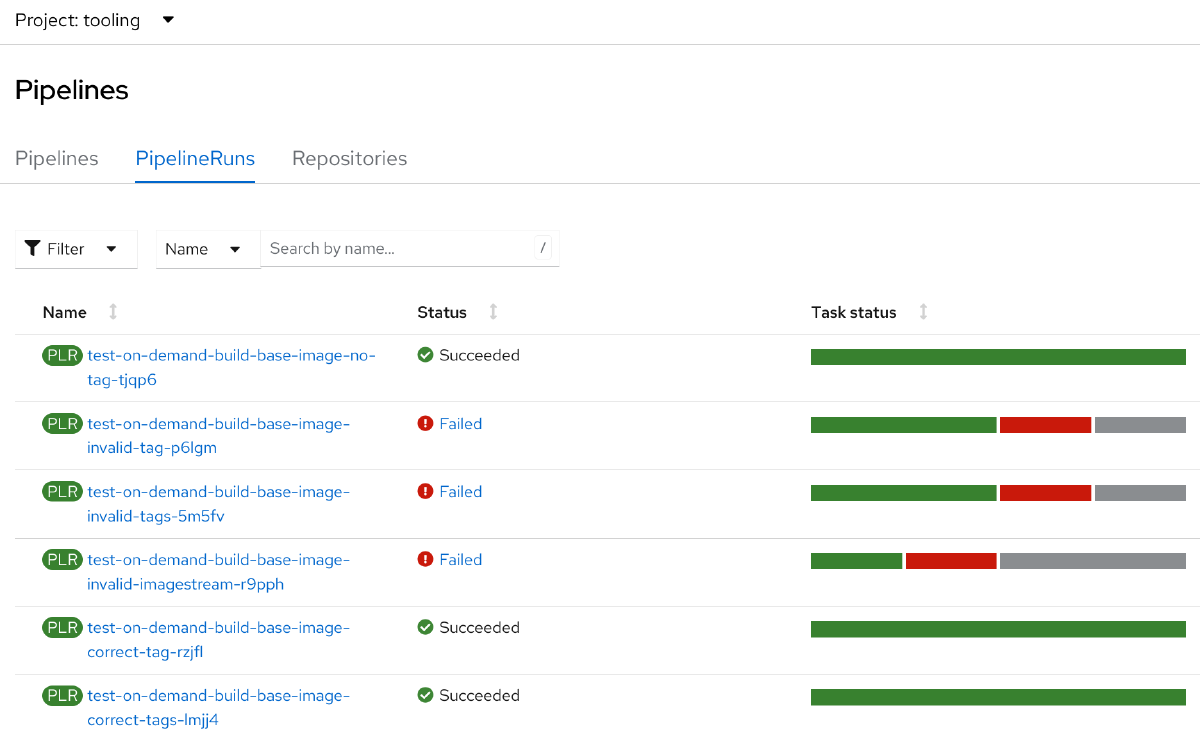
Deze afbeelding laat zien dat er een aantal tests niet slagen. De PipelineRuns die niet slagen zijn de volgende:
test-on-demand-build-base-image-invalid-tag-tjqp6test-on-demand-build-base-image-invalid-tags-5m5fvtest-on-demand-build-base-image-invalid-imagestream-r9pph
Deze tests hebben allemaal ongeldige componenten en moeten dus falen en afgevangen worden, wat we terug zien in het overzicht. De overige PipelineRuns slagen allemaal wel, wat ook volgens verwachting is, omdat deze geen verkeerde input bevatten.
Dus bij wijzigingen in de handmatige variant, of een van de Tasks, is het mogelijk om met een enkel script alle scenario’s af te vangen en zo de werking van de Pipeline te controleren.
Kleine kanttekening: Wanneer er teveel PipelineRuns zijn van het testen kunnen deze eenvoudig worden opgeruimd met een clean script wat ook in Git te vinden is. De tektonconfig op je platform heeft ook een ingebouwde pruner waarin via Cron een schedule meegegeven kan worden zodat Tekton deze zelf opruimt. Wanneer dit niet is ingesteld of je snel oude PipelineRuns wilt opruimen, kan dat prima met het meegeleverde cleanup script.
Open source
Last but not least, om het nog wat mooier te maken, deze software is volledig open source!
Wanneer je na het lezen van deze blog graag een feature ziet, of na het testen nog ergens tegenaan loopt, maak dan vooral een issue of merge request aan.
Ik zie graag feedback, features en bugfixes tegemoet.
Hier vind je de Git repository van de HCS Base Updater.
Hoe verder?
Aan het einde van de vorige blog heb ik geschreven dat er al snel een vraagstuk naar voren kwam over het handmatig starten van de pipeline.Er was behoefte aan de on-demand pipeline. Nu deze variant van de pipeline er is, zijn er een aantal dingen die de HCS Base Updater in de toekomst misschien nog mooier maken. Hierover heb ik een paar ideeën:
- Een simpele frontend met een webpagina toevoegen waarbij de configuraties voor het bouwen van images te beheren zijn en ook handmatig pipelines gestart kunnen worden;
- Wat ook leuke toevoeging kan zijn is een Tekton EventListener maken waarbij een pipeline gaat lopen wanneer er in Git een wijziging wordt gedetecteerd. Hierdoor wordt er ook een nieuwe image gemaakt wanneer er iets in de configuratie of Dockerfile/Containerfile is gewijzigd.
Allemaal leuke features en toevoegingen die de HCS Base Updater mogelijk nog uitgebreider en toegangkelijker maken.
Wanneer een van deze features, of andere leuke toevoegingen, in de toekomst aan de HCS Base Updater worden toegevoegd zal er weer een blog verschijnen.

 Thijs Gravestijn
Thijs Gravestijn


